グループ紹介
ふんが研では, WASMII, ASAP, BLACKBUSの3つのグループにわかれて研究をしています.
以下でそれぞれのグループを詳しく紹介していきます.
(現在掲載中の研究内容は2013年度現在のものです)
以下でそれぞれのグループを詳しく紹介していきます.
(現在掲載中の研究内容は2013年度現在のものです)
WASMII
WASMIIではスマートフォンなどの組み込み系向けに低電力で高性能なアーキテクチャの設計を行っています.
実際にチップを作成することもしています.
WASMII内ではさらに3つのサブグループに分かれています.
WASMII内ではさらに3つのサブグループに分かれています.
MuCCRA
動的再構成プロセッサ
MuCCRAは「Multi-Core Configurable Reconfigurable Architecture」の略で,このグループでは動的再構成プロセッサというアーキテクチャの有効的な利用方法を研究をしています.動的再構成プロセッサとは,チップの中に構成情報を流すことで動的に回路構成を変えることのできるプロセッサのことです.マルチメディア処理で性能を発揮できるアクセラレータと言えます.マルチコア化,無線での3次元接続など,さらなるパフォーマンスの向上に取り組んでいます.

CMA
低電力再構成プロセッサ
CMAとは「低消費エネルギー大規模再構成プロセッサアレイ」のことでCool Mega Array の略称です.名前にもある通り何よりもエネルギーを抑えることを優先したプロセッサです.MuCCRAの研究の結果,消費される電力のうち動的再構成に要する電力が意外に大きいことが判明したので,演算器をあらかじめ多数用意して一気に構成してしまい「動的」な再構成をしないのはどうだろうかという結論に至ったことが発端となり立ちあがったグループです.いままでにCMA-1, CMA-2の実機を作ってきました.WASMIIの中でもホットなグループです.

LEAP
超低電力アーキテクチャ
LEAPは, 「Low-power Electronics Assciation & Project」の略で,
SOTB CMOSFETと呼ばれる超低電力半導体を用いたアーキテクチャを設計しています.
SOTB CMOSFETはルネサスが開発した技術で, 従来は約1.2Vでチップを動かしていたものをこの技術を使うことにより約0.4Vと従来の1/3の電圧で動くようになり, 大幅に消費電力を削減することができるようになりました.
このSOTB CMOSFETを有効活用できるようにするのがこのグループの課題です.
SOTB CMOSFETをどのように制御すればいいかを探っています.
CUBE
三次元積層マルチコアプロセッサ
Cubeとは「誘導結合を用いたビルディングブロック型計算システム」の研究で作成された三次元積層プロセッサです。ビルディングブロック型計算システムとはおもちゃのLEGOを組み立てるようにして、チップ同士をくっつけることで用途に応じて様々なシステムを作成するものです。Cubeグループでは実際のシステムを作りながらソフトウェアから回路まで広い分野の研究をしています。

ASAP
ASAPではFPGAやGPUといった既存のデバイスを使って, でかい問題(計算量の多い問題)をできるだけ安いコストでいかにして速く解くかを追及しています.
画像処理, 流体力学, 金融工学など, 対象となる分野はたくさんあります.
ASAPでは以下の2つのサブグループに分かれています.
ASAPでは以下の2つのサブグループに分かれています.
FPGA
FPGAを用いたアプリケーション高速化
FPGAグループではFPGAによるアプリケーションの実行速度の向上についての研究を
しています.一言で言うと,ゴリゴリコーディングしてアプリをガッツリ速くするグループです.FPGAは,プロセッサ実験で使った自由に回路を書き換えられるデバイスで,周波数は低いですが,うまく並列性を抽出してあげればIntelのCPUの2~10倍の速度で処理することが出来ます.
現在は,流体力学アプリケーションの並列性抽出による高速化の研究を行っています.並列性を抽出してアプリ専用に演算器を並べで処理時間を短縮したり,動的に回路を書き換えて一つのFPGAでは載らない回路を実装
したり,Out of Order機構を実装して処理効率を向上させたり,様々なアプローチで高速化を追求しています.
こういったアプリケーションはVerilog-HDLで記述されていて,FPGAで限界性能を出すためには人柱…人月が必要になります.また,自力で並列性を抽出するのは大変です.そんなの嫌だという人には,C言語ベース(高位合成言語)での設計やバイナリから並列性を抽出して半自動高速化を行う研究もやっています.
高位合成は博士課程の学生が
本を翻訳出版されていたりと,ホットな分野です.
皆さんも限界追求の世界的なビッグウェーブに乗りませんか!?AA(ry
キーワード:高速化,FPGA,動的再構成,高位合成,並列化
キーワード:高速化,FPGA,動的再構成,高位合成,並列化

GPU
GPUを用いたアプリケーション高速化
皆さんはGPUをご存知でしょうか?
GPUはパソコンのグラフィックボードに載っている,画像処理に特化したプロセッサです.
最新GPUにはCPUのコア数とは比較にならない,なんと数千コアが搭載され3Dなどの重い処理を軽快にしてくれます.
こんなすばらしい処理能力を持ったGPUに画像処理しかやらせないなんてもったいないので, 我々はGPUの多目的での利用の研究を行っている訳です.
GPUグループの研究は一言でいえば高速化ということになります.
特定のアプリケーションを速くなるように実装したりはもちろん,フレームワークなどを作成してGPUをプログラムしやすくするツールを作成したり,
クラスタなどの接続網を工夫したりなど様々なアプローチを行っています.
そのためアプローチ方法次第で自分の得意分野をいかようにも生かせます.
キーワード:GPU,高速化,並列化,Verilog読み書き不要, GPU-BOX
キーワード:GPU,高速化,並列化,Verilog読み書き不要, GPU-BOX
BLACKBUS
BLACKBUSではチップ内の計算資源(CPUコアなど)を繋ぐネットワーク(Network on Chip)や,
スパコンやデータセンターで使われるネットワークについて研究しています.
計算処理を早くするにはCPUコアやコンピュータ(サーバ)を増やすのが手っ取り早いです.
しかし数を増やすとそれらを繋ぐネットワークの通信量が増えてしまうため, 効率のいいネットワークを考える必要があります.
松谷研究室の松谷先生および松谷研の一部学生もこのグループに所属しています.
松谷研究室の松谷先生および松谷研の一部学生もこのグループに所属しています.
Network on Chip
チップ内のネットワーク
Network on Chipでは, マルチコアプロセッサ上のコア同士を従来のバス接続ではなく,ネットワークによって接続しパケットを流して計算を行います.
パケットをいかに効率よく流すか(ルーティング), パケットを流すルータをどのように設計するかが主な研究テーマとなります.
最近では次世代のチップであるワイヤレス3次元積層チップを対象としたネットワークの研究をしています. ワイヤレス積層チップは, 重ねたチップ間の通信をワイヤレスで行うことで自由にチップの構成を変えることを可能にしようといった目的で, ふんが研内でプロジェクトが進められています. 最近世界で初めて実機で動作することを確認し, これからどんどん話題になっていくものと考えられます. 皆さんも次世代のネットワークを作ってみませんか?
最近では次世代のチップであるワイヤレス3次元積層チップを対象としたネットワークの研究をしています. ワイヤレス積層チップは, 重ねたチップ間の通信をワイヤレスで行うことで自由にチップの構成を変えることを可能にしようといった目的で, ふんが研内でプロジェクトが進められています. 最近世界で初めて実機で動作することを確認し, これからどんどん話題になっていくものと考えられます. 皆さんも次世代のネットワークを作ってみませんか?

スパコン・データセンター
高性能なネットワーク
スパコンやデータセンタでは, コンピュータや通信装置を納めているラックが使われています. ラックは年々増加傾向にあり, Googleのデータセンターではすでに数十台のサーバを納めているラックが数十万台設置されています.
ラックが増えるとネットワークが大きくなり, 通信量も増大してしまいます. そのため, ネットワークがしょぼいと全体の性能が落ちてしまいます. 例えば先ほどのGoogleだと, ユーザーが検索をかけてから結果が表示されるまでの時間が長くなってしまうなど, 利用しているユーザーにも影響がでてしまいます.
このグループではたくさんのデータを捌き切るための効率のいいネットワークを追求しています.
ラックが増えるとネットワークが大きくなり, 通信量も増大してしまいます. そのため, ネットワークがしょぼいと全体の性能が落ちてしまいます. 例えば先ほどのGoogleだと, ユーザーが検索をかけてから結果が表示されるまでの時間が長くなってしまうなど, 利用しているユーザーにも影響がでてしまいます.
このグループではたくさんのデータを捌き切るための効率のいいネットワークを追求しています.

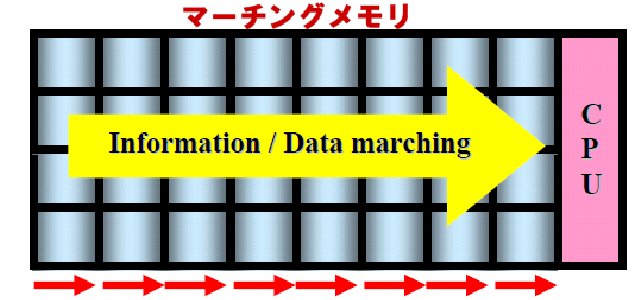
マーチングメモリ・プロジェクト
マーチングメモリとは
計算機の基本的な設計コンセプトは,フォン・ノイマンなどによって60年以上も前に考えられて以来,ほとんど変わらずに今日まで使われつづけています.プログラムをメモリに格納し,それを読み込んで実行していくという方式です.この方式では,プログラム実行速度が速くても,メモリへのアクセスに時間がかかるため計算機の性能は制限されてしまいます.
マーチングメモリ(Marching Memory, MM)はこのメモリ・ボトルネックをなくすメモリとして発明されました.プロセッサがデータにアクセスするのではなく,データがクロックに同期して列から列へと隊列進行(marching)することでプロセッサ付近に到達し,プロセッサは付近に固定されたポートにアクセスするだけでよく複雑で時間のかかるアドレッシングが必要なくなります.これによってアクセススピードは驚異的に向上します.
マーチングメモリスルータイプを用いたNoCルータ 我々は,ルネサス エレクトロニクスとの共同研究において,このマーチングメモリの「データが移動する」という考え方を用いてマーチングメモリスルータイプというメモリを開発しました.これは低消費電力を主眼におき,データの移動をクロックと非同期で行います.このメモリはFIFO構造で小容量,高速,低消費電力でありNoCルータへの使用に適しています.このメモリをNoCルータのインプットバッファ(パケットを貯めておくところ)に用いることで,低消費電力のルータを実現することができます. NoCプロセッサにおけるルータの消費電力は約30%を占めており,このオーバヘッドを削減するのは重要だと言えます.
マーチングメモリスルータイプを用いたNoCルータ 我々は,ルネサス エレクトロニクスとの共同研究において,このマーチングメモリの「データが移動する」という考え方を用いてマーチングメモリスルータイプというメモリを開発しました.これは低消費電力を主眼におき,データの移動をクロックと非同期で行います.このメモリはFIFO構造で小容量,高速,低消費電力でありNoCルータへの使用に適しています.このメモリをNoCルータのインプットバッファ(パケットを貯めておくところ)に用いることで,低消費電力のルータを実現することができます. NoCプロセッサにおけるルータの消費電力は約30%を占めており,このオーバヘッドを削減するのは重要だと言えます.