WASMIIでは, スマートフォン, IoT, ウェアラブルデバイスなどの組み込み系に向けて, チップ開発をしています. 組み込み系では, 長期間バッテリー駆動できることが望ましいので, 低電力がメインテーマです. チップの設計も行っており, テープアウト(設計締め切り)の直前には, ふんがさんをはじめ, 研究室全体が活気づく様子が見られます. WASMII内で現在行われている研究は以下です.

Cubeとは「誘導結合を用いたビルディングブロック型計算システム」の研究で作成された三次元積層プロセッサです.
「積層? 通信はどうするの?」
いい質問です.
電磁誘導を使って通信をします.
慶應電子工学科黒田研から, TCIというモジュールが提供されています.
アプリケーションに特化したチップ同士を積み上げることで, 用途に応じて様々なシステムを作成しています. 現在では, CMAというリコンフィギュラブルシステムを積層する計画が進んでいます.

CMAとはCool Mega Arrayの略です. 分野としては, CGRA(Coarse Grained Reconfigurable Array)と呼ばれるジャンルですが, 再構成の頻度を減らすことで大幅な低電力化を達成しました. 名前にもある通り何よりもエネルギーを抑えることを優先したプロセッサです.
MuCCRAの研究の結果,消費される電力のうち動的再構成に要する電力が意外に大きいことが判明したので, 演算器をあらかじめ多数用意して一気に構成してしまい「動的」な再構成をしないのはどうだろうかという結論に至ったことが発端となり立ちあがったグループです.
Geyserは, Cubeシステムにおいて, 計算の指揮を取るCPU部のチップです. 現在は, このCubeタワーが2つ横並びになった「ツインタワーシステム」が提案されています. 2つのタワーは共有メモリSMTTを介して通信します. 2017年度夏季にSMTTのテープアウトがありました.
近年, 画像認識や音声認識, 機械翻訳などの分野において, Deep Learningが幅広く利用されるようになりました. Deep Learningの高速化には, 本来ゲームの高速化用であったGPUを用いることが一般的です. しかし, 電力効率などの面において, コンピュータアーキテクチャの観点から, さらなる効率化の余地があるものと考えられます.
天野研究室では, Deep Learningをターゲットとして, 電力や速度の面で既存のCPUやGPUよりも有利な, 新しいアクセラレータ, NeuroCoreの開発に取り組んでいます. SNACCというチップを開発しました. 畳み込み演算に特化したASICです. 具体的には, 独自の命令セットを持つメニーコアアーキテクチャを採用しています.
MOS-FET(トランジスタの一種. 現在のコンピュータシステムで最もよく用いられている)のウェルに電圧をかけることで, ゲート(≒トランジスタ)の動作速度を上げたり下げたりします. トランジスタはOFFからONに切り替わる際に消費する「(動的)スイッチング電力」と, 何もしなくても流れ続ける「(静的)漏れ電力」の2つが存在します.
フォワード・バイアスをかけると, ゲートの動作速度が上がりますが, 代償として漏れ電力が増加してしまいます. 逆に, リバース・バイアスをかけると, ゲートの動作速度は低下しますが, 漏れ電力を削減することができます. この条件のもとで, 最適な電力点を発見するシステムの提案を行っています.
不揮発性の記憶素子を実現する方法の一つにMTJを用いる方法があります. MTJ素子は磁場の向きによって素子の抵抗が変化することを利用して情報の格納を行うことができます. その不揮発性から, 長時間データをキープしたり, 電源をオフにしても(パワーゲーティングしても)データが失われないという特質があります. 一方で, 書き込みに大きな電力を必要とするという欠点もあります. 大きい書き込み電力による影響を軽減するため, いささか洗練された制御が必要とされます. ふんが研では, 書き込み電力を削減するための制御を実現しながらパワーゲーティングできるアーキテクチャの研究を行なっています.

MuCCRAは「Multi-Core Configurable Reconfigurable Architecture」の略で, このグループでは動的再構成プロセッサというアーキテクチャの有効的な利用方法を研究をしています. 動的再構成プロセッサとは,チップの中に構成情報を流すことで動的に回路構成を変えることのできるプロセッサのことです.
MuCCRAはマルチメディア処理で性能を発揮できるアクセラレータと言えます. マルチコア化,無線での3次元接続など,さらなるパフォーマンスの向上に取り組んでいます.
LEAPは, 「Low-power Electronics Assciation & Project」の略で, SOTB CMOSFETと呼ばれる超低電力半導体を用いたアーキテクチャを設計しています. SOTB CMOSFETはルネサスが開発した技術で, 従来は約1.2Vでチップを動かしていたものをこの技術を使うことにより約0.4Vと従来の3分の1の電圧で動くようになり, 大幅に消費電力を削減することができるようになりました. このSOTB CMOSFETを有効活用できるようにするのがこのグループの課題です. SOTB CMOSFETをどのように制御すればいいかを探っています.
ASAPでは単体FPGAやGPUボードを使って、複雑な問題(計算量の多い問題)をできるだけ安いコストでいかにして速く解くかを追及しています。深層学習、画像処理、音声認識、流体力学や金融工学などを対象となる分野は沢山研究されています。研究テーマによって、いくつかのチームにわけています。以下は研究チームによって、存在しているプロジェクトをご紹介いたします。


ローエンドのエッジデバイスにおいて最先端の AI アプリケーションを動かすためには、高い消費電力と 計算リソース不足という 2つの問題があります。本研究はこれらの問題を解決するために、効率が高く高速処理 ができることで知られるプラットフォームである FPGAを適用しました。開発プラットフォームは低コストだがリソースが少ないボード PYNQ-Z1 を選びました。対象アプリケーションとして、ニューラルネットワークを利用した高性能な物体検出システムである YOLOシステムを選択しました。本研究の目的は、このニューラルネットワークシステムを GPU からローエンドデバイスに移行させることです。

CLAHEは画像のコントラストを強調し画像の品質 を改善する処理であり、幅広い分野で応用されています。CLAHE には多くのバリエーションが存在するため変更容易性は重要であります。したがって、変更容易性や保 守性に優れた高位合成を使って CLAHE の実装を考えることは価値があると考えております。CLAHE を高位合成を用 いて低価格 FPGA ボードに実装を行いました。我々はコードをデータがストリーミングで流れるように変更を施すことに より、入出力 1 ピクセル/1 クロックサイクルという条件下でのクロックサイクルの下限の約 1.10 倍のクロックサイク ルで実行できるデザインを作成しました。
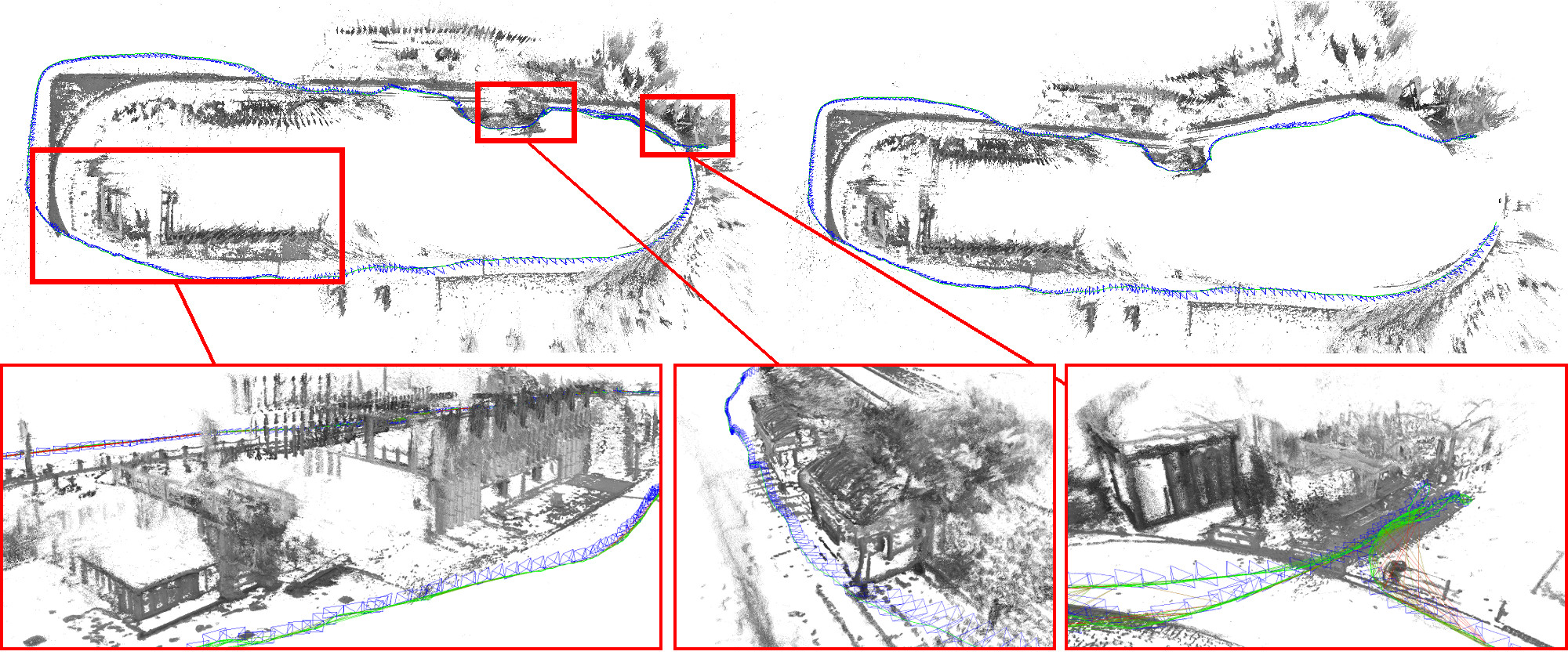
SLAMとは、Simultaneous Localization And Mappingの頭文字を取ったもので、「自己位置推定」と「環境点の3Dマッピング」を同時に行うものです。GPSの使えない屋内環境や、環境の3D復元を行いたいときに用いることができます。自動運転・ドローン・レスキューロボットに用いることができます。現在、活発に研究が行われているのは、画像のみから、特徴点を使ってカメラの動きを推定する「Visual SLAM」と呼ばれるものです。
[わかりやすいビデオ]
ASAPグループでは、このVisual SLAMをFPGA・GPUに実装し、ドローンや自律ロボットに簡単に載せられるようにする研究を行っている人もいます。
人は色々な音か聞こえる多様な環境で音を「聞き分けて」処理を行い、実環境で聞こえる多様な音を様々なレヘルで処理するための機能を包含する必要かあります。 ロホット聴覚ソフトウエア HARK は『聴覚の OpenCV』を目指したシステムです。HARKは入力から音源定位・音源分離・音声認識までの総合機能の提供するシステムです。東京工業大学の中臺研から開発されました。今おシステムについて詳しい情報は HARK Document で載せています。消費電力効率や計算量の複雑さなど、いろいろな面を考えた上で、音声チームは音源定位・音源分離この二つの部分をHARKシステムから抽出して、FPGA高速化処理を行います。
Aeroプロジェクトでは,FPGAを用いた数値流体力学/粒子法アプリケーションの高速化の研究をしています. FPGA(Field Programmable Gate Array)は現場でプログラム可能なゲートアレイで,その利点を生かしてアルゴリズムに合わせた並列回路を記述し, 高性能計算を行います.現在はホールスラスタと呼ばれる衛星エンジンの開発に用いられるシミュレーション(PIC法)コードの高速化に取り組んでいます. FPGA回路の記述には,C言語ライクに開発が行える高位合成環境を用いています.

単細胞アメーバ生物・粘菌が自然界をたくましく生き抜くチカラに注目しています。アメーバが環境に適応し最適なパターンに変形する振る舞いに学び、「巡回セールスマン問題」や「充足可能性問題」などの複雑な組合せ最適化問題の解を求められます。電子回路を用いて高速に探索する生物型コンピュータの研究を続けてきました。汎用性の高いアルゴリズム「AmoebaSAT」とFPGAコンピューティングを組み合わせ、新方式の「アメーバコンピュータ」を開発しています。1枚のFPGAボードMKBOSで、最大3万変数の組み合わせ最適化問題を1秒以内に解けられます。モノの自動搬送システムやスケジュールの最適化といったモノづくりやモノの流れを、エッジデバイス上で小型かつ低消費電力で最適化できます。
FPGAやGPUを利用して高速化, 低電力化を図るのではなく, エッジデバイスからクラウドまで適用できる汎用性のある機械学習用プロセッサの研究をしています. プログラム可能なプロセッサとして設計することでアクセラレータしての制約をなくします. また, 機械学習用途向けのプロセッサとして設計することでGPU以上の実行性能と低消費電力の両立を目指します. そして推論だけでなく学習に対しての実行性能も高くかつ消費電力が低いデバイスのアーキテクチャを探索します.

最近ではGPUを組み込むことで性能向上を目指すスパコンが増加しています. GPUはCPUから計算に必要なデータを受信して, 計算結果をCPUへ送信する必要があります. また他のGPUにデータを送りたいときもCPUが必要となります. 例えばCPU_Aに繋がれたGPU(GPU_A)から他のCPU(CPU_B)に繋がれたGPU(GPU_B)にデータを送りたいという時でも, わざわざGPU_A → CPU_A → CPU_B → GPU_B とデータを転送しなければいけません. GPUを利用したスパコンでは特に, 別のCPUに接続されたデバイスにデータを送るのが遅いのです. そこで開発されたのがTCAアーキテクチャです. TCAアーキテクチャは, PEACHとよばれるFPGAで作られたスイッチによりCPUで隔てられたGPUを直接接続することが可能で, データ転送を高速化することが出来ます. つまりGPU_A → GPU_Bです! また, PEACHに利用しているFPGAは高性能でまだまだ性能的に余裕があります. このPEACHを利用して様々なアプリケーションの高速化を研究していました.
近年, CPUやGPUを利用する際にバスとしてPCIeが利用されており, PCIeを利用するデバイスが増えてきています. そのため, PCIeを拡張するためにExpEtherという技術が開発されました. ExpEtherはEthernetを基盤とした仮想化技術ですが, Ethernetを利用しているため,通信バンド幅が小さくなっています. そのため, 我々は通信バンド幅を大きくするために送信前にデータを圧縮し, 送信先でデータを伸張することでデータの通信バンド幅を向上させようという試みをしています. なお,このExpEtherはFPGAに実装されており, 実装されたFPGAの空容量を利用して実装を行います. 現在は, グラフデータやDeep Learningで利用するデータを対象としており, そのための圧縮アルゴリズムの開発と実装を行っています.
FiCでは, 5Gの無線基地局やクラウドに設置する計算基盤となるようなマルチFPGAシステムFlow-in-Cloudを開発しています. 電力効率が良く低遅延での処理が得意なFPGAを複数繋げることで電力制限が厳しいような環境にも強力な計算基盤を実現することができます. 実システムとして利用できるように, アーキテクチャの研究だけでなく実際のアプリケーションを想定した並列化や高速化の検討, FPGA同士の通信の効率化, 基盤として使うためのソフトウェアスタック, 開発ツールなど多岐に渡るトピックで研究に取り組んでいます. 企業や他大学との共同研究も多いです. ※図が小さめですが, クリックすると拡大されるのでぜひ拡大して見てください.
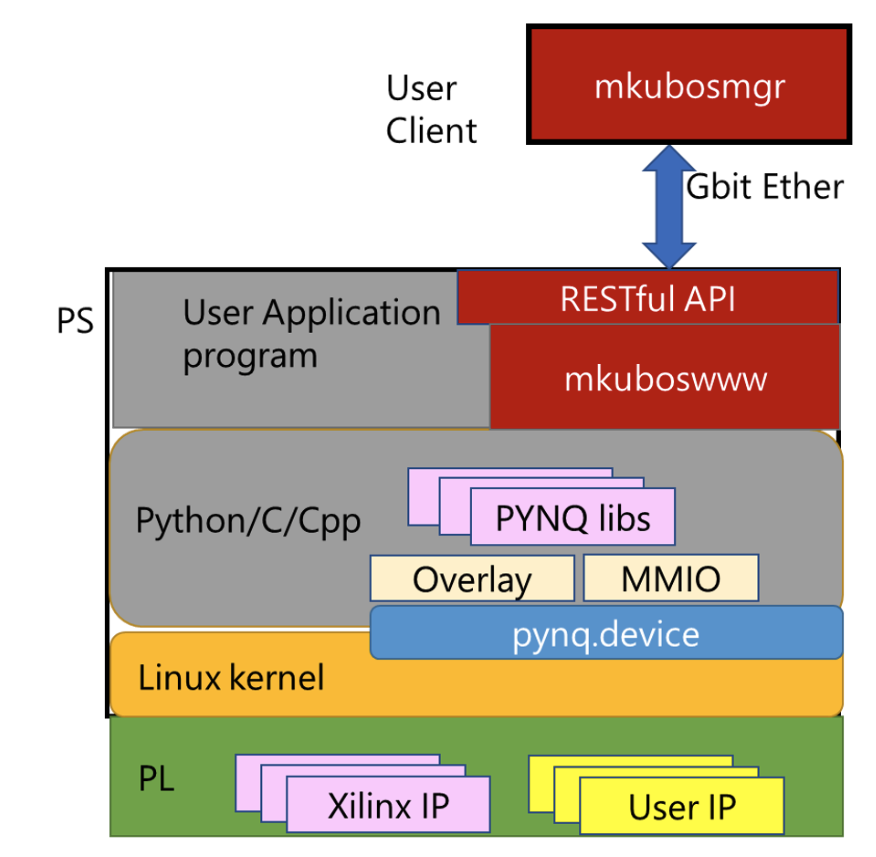
Web API経由でFPGAをコントロールするソフトウェアスタックの実装に取り組んでいます. ブラウザやコンソールから簡単にFPGAの設定や制御ができるように図のようなソフトウェアスタックをLinux上に実装することで, リモートでの制御ができるだけでなく, 複数枚のボードに設計した回路のコンフィギュレーションや通信の設定が一括で行えるようになりました.
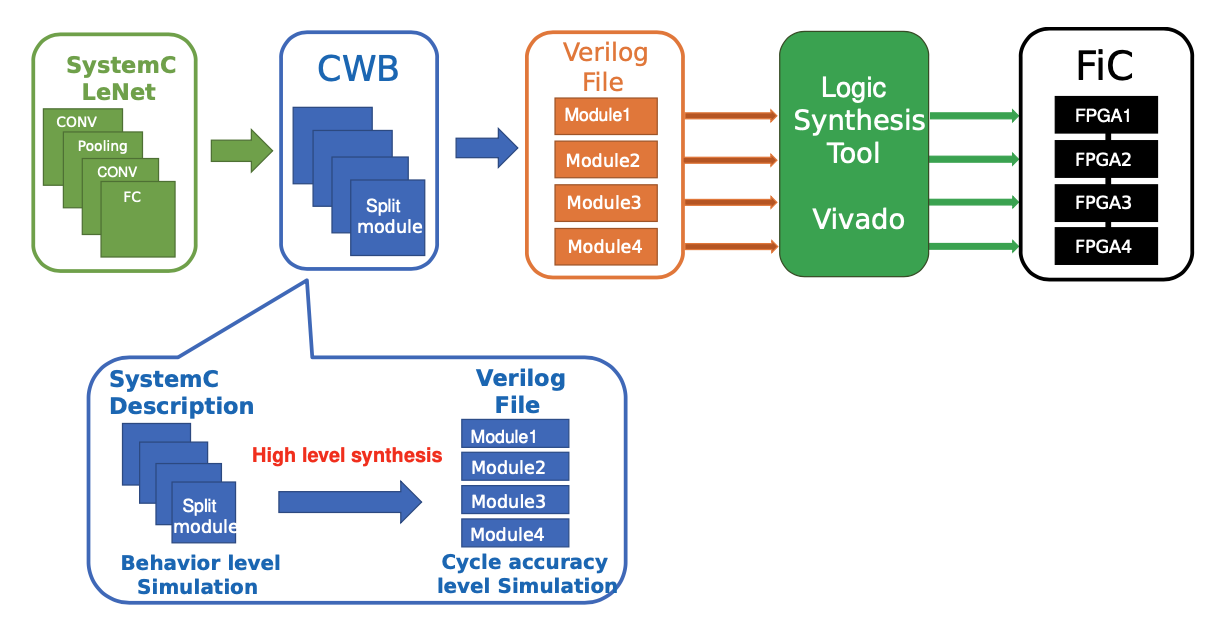
従来のFPGA開発ではVerilogなどのHDL(ハードウェア記述言語)を使って開発することが多かったのですが, C/C++などで書いたアプリケーションをFPGAの回路に変換してくれる高位合成という技術も取り入れられるようになりました. この研究では通常のソフトウェア開発と同じように記述されたC言語のプログラムを複数枚のFPGAに自動分割して実装できることを目指しています. 実現できるとより便利にマルチFPGAを利用することができます. また、無線基地局などで想定されるタスクをマルチFPGAのどのボードで実行するのかを自動で割り当てるアルゴリズムの研究にも取り組んでいます.
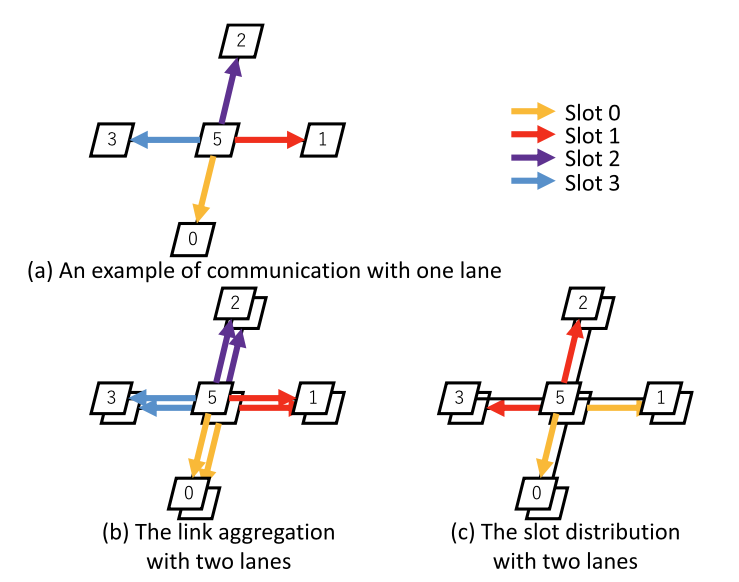
FPGA間の通信性能を向上させるためのネットワーク多重化の方法について、検討・実装しています. FiCのベースとなる時分割多重通信方式で物理ケーブルの性能を十分に発揮するために, 異なるタイムスロットの通信を複数あるレーンに分配する方法や 複数レーンを束ねて利用する方法などを考案し実装し性能評価を行いました.
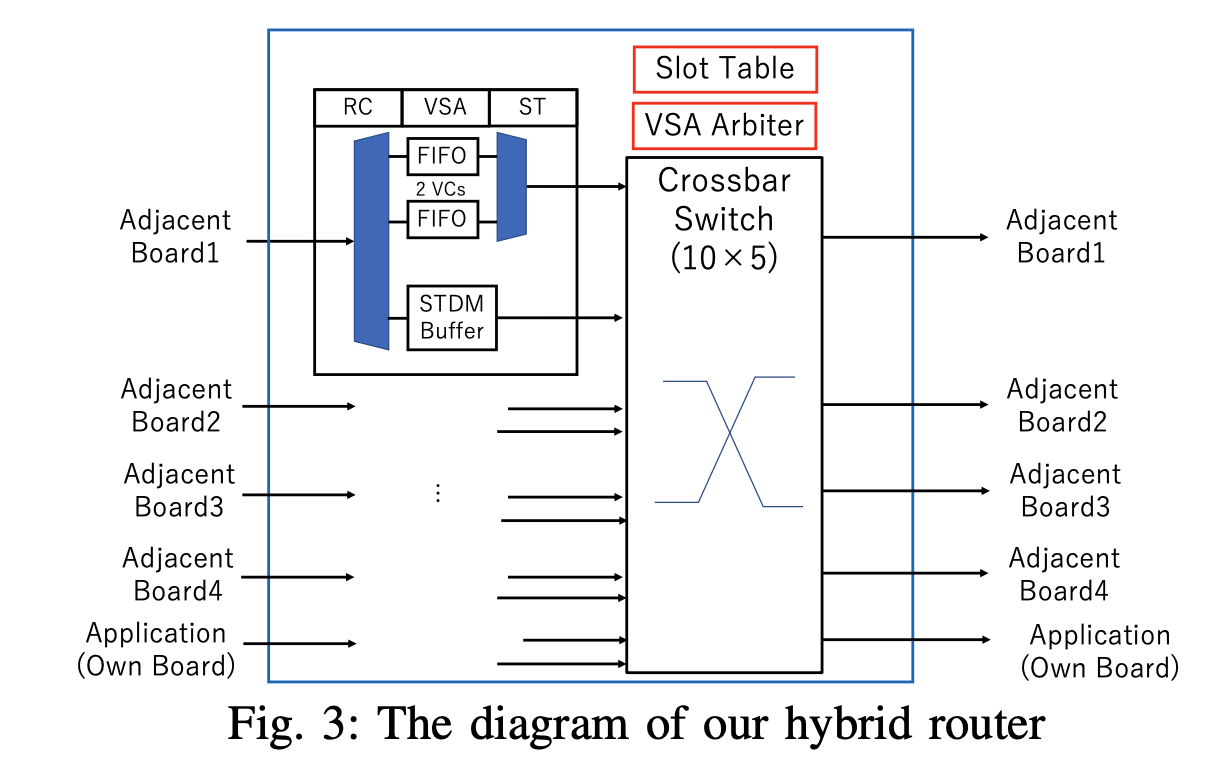
現在使われている時分割多重の通信方式とパケットルータの両方を搭載したハイブリッドルータを実装し, 通信パターンやアプリケーションの種類によって利用するルータを切り替えて効率の良い通信を実現しようとしています. どちらのルータを使うと通信性能を最大限引き出せるのかを考慮したアルゴリズムの検討にも取り組んでいます.
実際に無線基地局やクラウドで高速化する需要があるアプリケーションを対象にFiCの複数枚のFPGAにデータフローを構築する, 分散処理させるなどの工夫を凝らしながら, 特定のアプリケーションをハードウェアレベルで高速化するDSA(Domain Specific Architecture)と呼ばれる近年のコンピュータアーキテクチャの考え方に基づいて 並列処理, エネルギー効率の良いアーキテクチャの研究にも取り組んでいます. 下記に上げるのはいくつかの例で, 他にもASAPグループと共同で音響アプリケーション・ロボット制御・アメーバの特性を生かした計算アルゴリズムなど様々なアプリケーションの高速化に取り組んでいます.
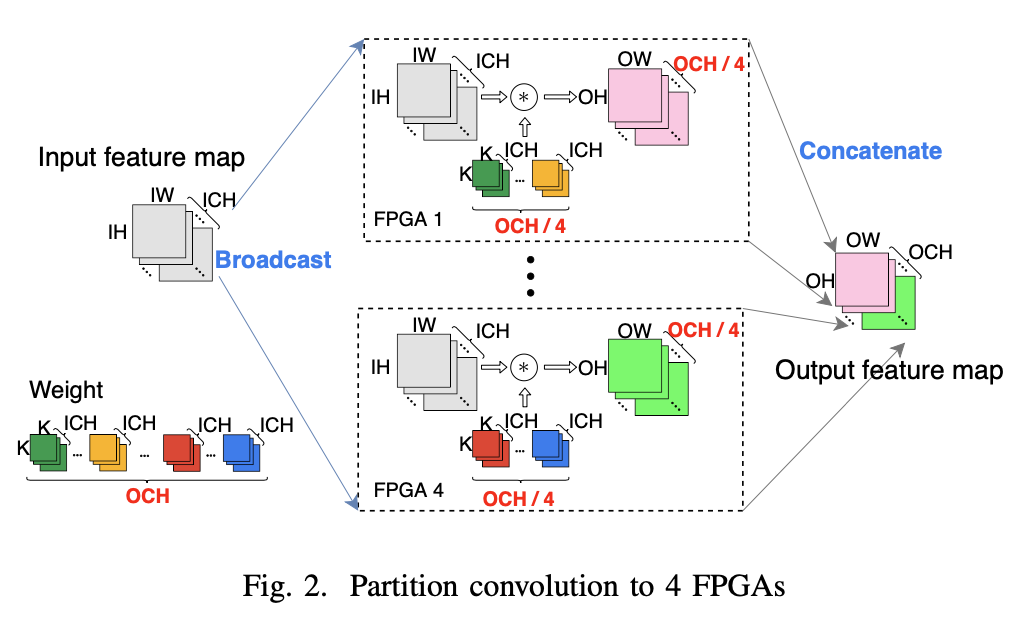
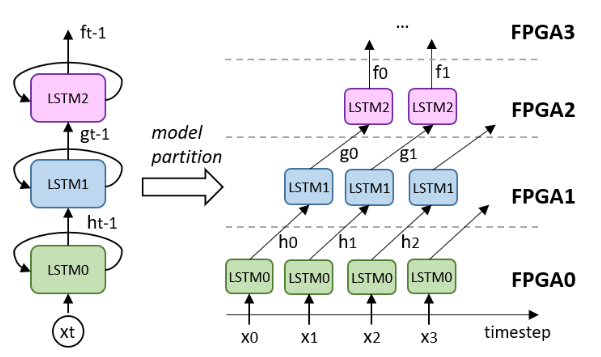
画像認識などに大きな効果を発揮するCNN(Convolutional Neural Network)や自然言語処理、時系列データ予測などに強いRNN(Reccurent Neural Network)の演算を FPGAで高速化しようという研究です. この分野ではGPUが圧倒的に強いのですが巨大な消費電力や利用効率が低くなってしまうという欠点もあります. FPGAを用いて, 電力効率良く実行し足りない計算パワーは複数枚に分散させてGPUに勝とうという魂胆です. 画像認識用のCNN(LeNet, AlexNet, ResNet-50)や時系列データ予測のLSTMが実際に実機で動いていてさらなる高速化, 利便性の向上などに取り組んでいます.
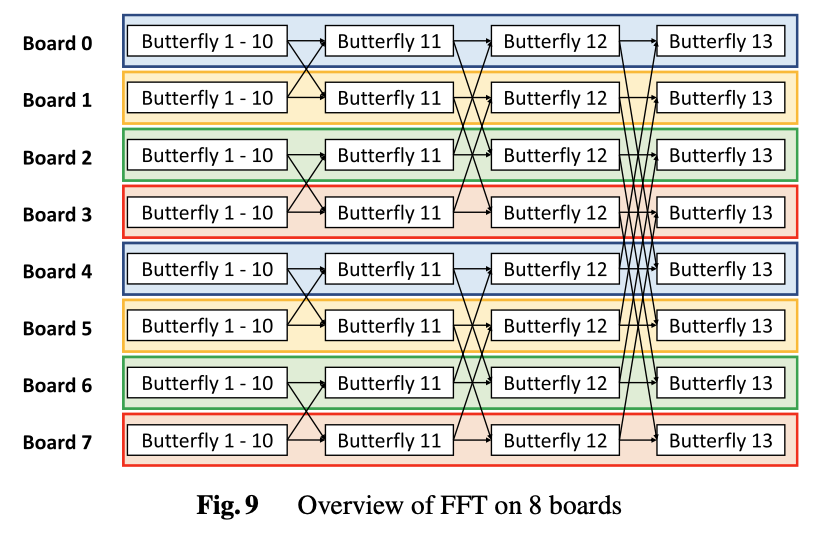
共役勾配法(連立方程式を解くためのアルゴリズム)や高速フーリエ変換を複数のFPGAで分散処理することで高速化を目指します. それぞれのボードでの計算結果をお互いに交換する必要があり, FPGA同士が直接通信することで効率よくデータ交換を行いながら計算します.
ゲノム解析のために必要なパターンマッチングをマルチFPGAで高速化することを目指します. 膨大なDNA鎖も複数のFPGAで分散して電力効率良く処理するために、アルゴリズムをFPGAで並列実行できるように設計しています.

このようにラックに4枚のFPGAが収まっていて, 青いケーブルでFPGAが同士が通信します. 今はより大きいラックに全部で24枚のボードが収まっているのでぜひ実物も見に来てください.
Blackbusは未来のコンピューターを考え, その可能性を研究するチームです. 主にスーパーコンピューターなどのHPC分野を視野に, 3次元積層や水没コンピューター, Approximate(近似)コンピューティング, Network-on-Chipなどの研究に取り組んでいます. Blackbusは情報工学科 松谷研究室や国立情報学研究所 鯉渕研究室と共同で研究しているチームで, ミーティングで3人もの教授・准教授の指導を受けられるのが魅力です. 1口で3倍美味しいチームです.
通常のコンピューターはExact、すなわち正確に計算することが常識です。 デジタルであることの強みは、その再現性にあるために多くの場合は暗黙的にビットレベルで正確であることが期待されています。 しかし、すべてのユースケースで本当にその正確さが必要かと言えば、決してそうではありません。 例えば画像や動画は非可逆圧縮により精度を落としているように、完璧な再現性を要求されないケースは多くあります。 これは急成長している機械学習などのAI系技術においても言えることで、 例えばGoogleのTPUでは計算に用いる浮動小数点数の精度を落とすことで性能を稼ぐことに成功しています。 アプリケーションが本当に必要としている精度とハードウェアが提供している精度との間にはギャップがあることが多々あるのです。
Approximate Computingはそのギャップである余計な精度を捨てて、代わりに性能やエネルギー効率に得ることを目指す領域です。 その中でもBlackbusグループでは通信ネットワークに注目したApproximate Computingの実現手法を研究しています。 ノード間通信とチップ内通信(Network-on-Chip)の両方を対象にして、 通信の超低遅延な非可逆圧縮などの手法を提案し、シミュレーションなどを駆使して評価しています。
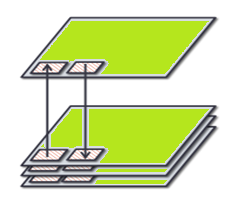
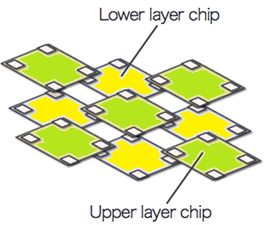
Blackbusグループでは高電力なプロセッサを水没させて冷却するという研究を行っています. 油などの電気絶縁性の高い液体であればプロセッサをそのままぶちこんでも勝手に動いてくれるのですが, 水にプロセッサを入れてしまうと壊れてしまいます. そのためパリレン膜という薄い樹脂をマザーボードごとコーティングすることで実機を動かしています. この水没技術を利用し, 高電力プロセッサを三次元積層することを考えています.
従来の以下のように3次元積層の方法では冷却効率が悪く温度が高くなってしまいます. しかし図2のようなTCI(誘導結合)を利用したCastele of Chips(CoC)の技術を利用することでより冷却性能を高めることが出来ます. しかしこれによってチップ間のネットワークの性能は落ちてしまいます. またチップとチップの重なっている部分を大きくするか小さくするかで通信性能と熱温度のトレードオフの問題もあります. またアプリケーションレベルの評価も考える必要があります. このようなトレードオフを考えながらよりよい三次元積層, 冷却方法を探求するような研究を行っています.
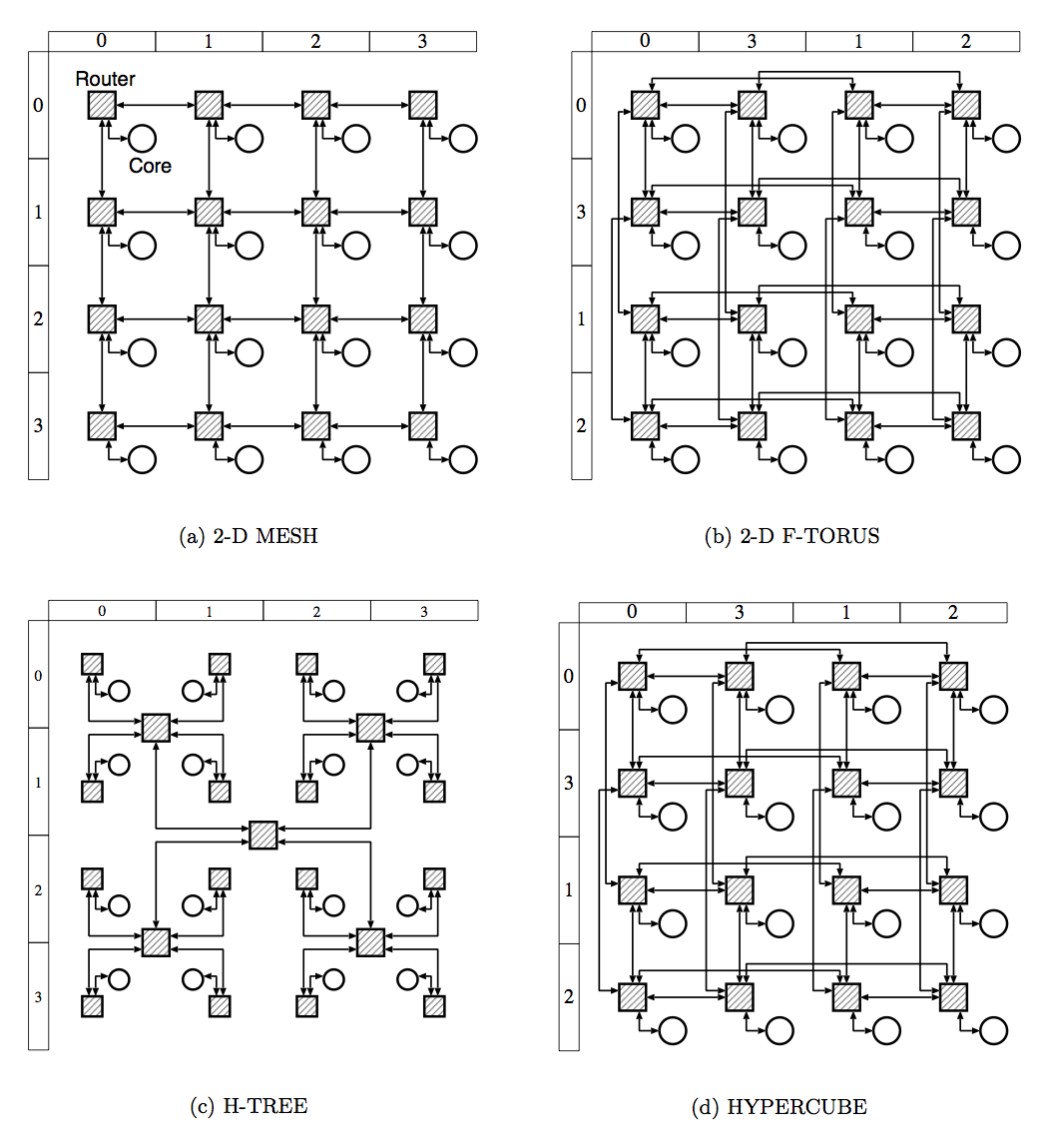

現在のプロセッサ内部には多くのコアやキャッシュメモリがあり, それらが多くの通信を行うことで高速なコンピューターを実現しています. しかし, どんどんチップが大規模化してくるとこの通信が性能向上の障害になります. 市販されているプロセッサでは多くの場合バス通信でプロセッサ内の通信を行っていますが, バス通信は共有しているバスを通信時に専有するため, コアが増えれば増えるほど通信性能が落ちます. これだとコア数が増えたときに通信待ちのせいで性能が発揮できないことになります.
Network-on-Chipはその名の通り, このプロセッサ(チップ)内の通信をルーターを経由して行うネットワークとすることで, 通信を多重化して同時並行で行えるようにする技術です. Blackbusではこのネットワークのトポロジの研究を行っています. NoCでは製造コストや配線長の削減のため, 図3に示すような規則的トポロジが使われてきました. しかしながら, これらのトポロジにはホップ数(送信元から送信先までの経由ルータ数)が大きくなり性能は良くないです. 実際のシステムのトラフィックを考慮し, 特定のアプリケーションに特化したトポロジを生成する手法として不規則的トポロジも提案されました.
Blackbusでは, 図4に示すようなスモールワールド現象を応用したランダムトポロジを研究しています. でたらめにリンクを張ると驚くべきことに通信性能が飛躍的に上昇するということが発見されました. 今後, 規則的トポロジの代替となることを目指しています.
最近の研究では, ランダムにリンクをつなぎ変える操作を何度も行うことにより, 数学的な理論限界に数パーセントの差の性能まで近づくことが明らかになっています. コンピュータ・システム, ネットワーク, さらには数学の知見を組み合わせた研究トピックにも取り組んでいます.
その他の情報はこちら
ふんが研ではYAMASHI(山師)と呼ばれるプロジェクトも存在しています. これは悪い意味ではなく,今まで研究してこなかった,まったく新しい研究テーマに挑戦しよう!というプロジェクトで, かなり斬新な研究が多いのが特徴です. ふんがさんがアイデアを出して学生を募集することもありますし,学生が主導してアイデアを出してプロジェクトを立ち上げることもあります. いずれにせよ,非常に刺激的な研究生活が待っているでしょう!