概要
音声認識や画像識別に用いられるニューラルネットワーク(以下NN)では大容量のデータと大量の計算処理が高性能化の大きな壁となっています。現在はNNの高速化にはGPUを使うのが一般的ですが、これでは将来くるであろうNNの大規模化には到底対応できません。
この問題を解決すべく、このプロジェクトでは高性能FPGAスイッチと省電力GPUを組み合わせたAIアーキテクチャの開発を行っています。このアーキテクチャでは、AIアルゴリズムの処理を効率的に行えるGPUを複数設置し、FPGAをスイッチとしてネットワークを構成します。ここで特徴的なのは、FPGA自体にも演算コアを加えることです。状況に応じてFPGAとGPUをうまく組み合わせてることで高性能化・低電力化を実現します。最終的には現在最高とされているAIエンジンに対して電力比で10倍以上の性能を発揮できることが目標です。
今年度から始まったこのプロジェクトは、慶應ふんが研だけでなく、産総研や東大、各企業など多くの外部機関が関わった大規模な計画となっています。
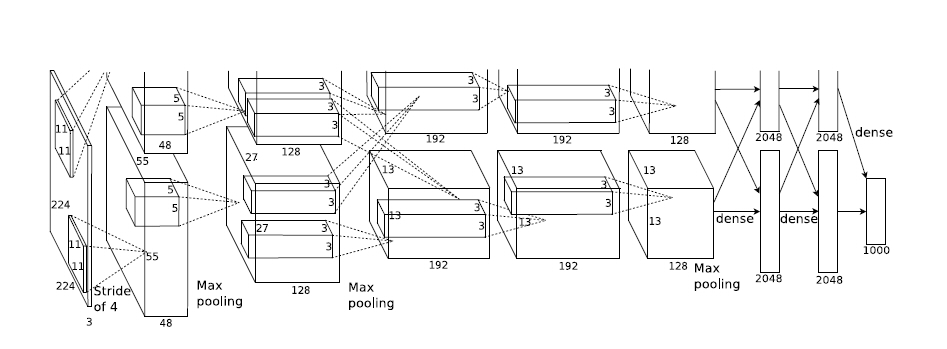
画像識別を行う畳み込みニューラルネットワークの例
(Krizhevsk et al., ImageNet Classification with Deep Convolutional Neural Networks, NIPS2012)
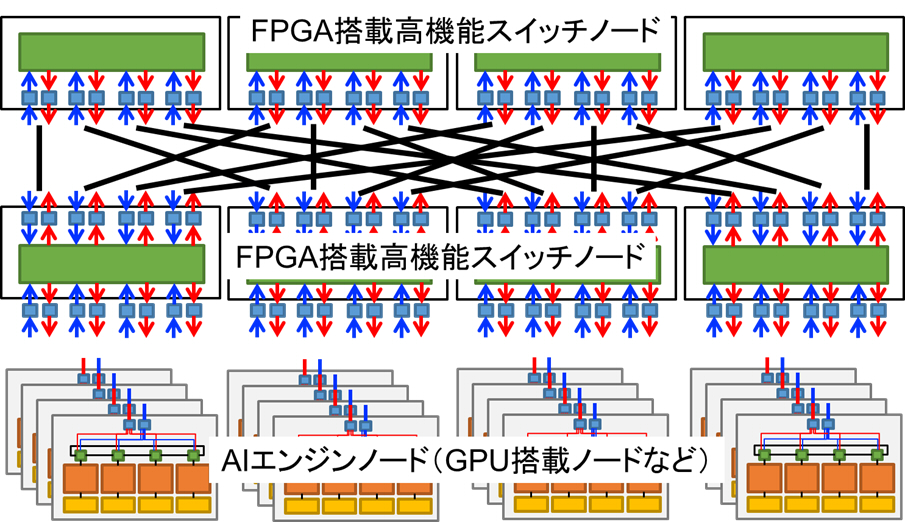
異種AIエンジン統合アーキテクチャの概要






